Destinations
We can summarize our philosophy with regards to data destinations like so:
- Businesses can get the most value out of their data when they build a deep understanding of their customers in one place, such as your Data Warehouse (this allows you to avoid silos and build the deepest possible understanding by combining datasets).
- Businesses should hold their customers’ privacy close to their hearts. It is something that is hard won and easily lost, so only the data that needs to be shared with third parties, should be.
Here you will find an overview of what’s available.
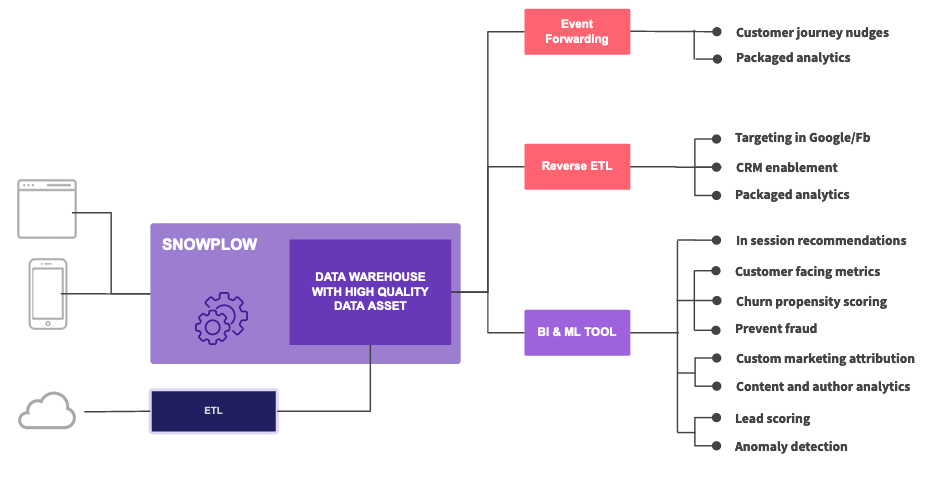
Data warehouses and lakes
Snowplow is primarily built for data warehouse and lake destinations and supports Redshift, BigQuery, Snowflake and Databricks, as well as S3 and GCS, via the various loaders.
Additional destinations
Snowplow supports sending your data to additional destinations through a variety of different options and tools.
No Processing Required (Event Forwarding)
This is the route to take if you want to forward individual events to downstream destinations, ideal for use cases where platforms can make use of event data, such as "evented" marketing platforms.
Snowplow recommends using Google Tag Manager Server Side to forward events to other platforms. This can be used in two configurations, either before or after the Snowplow pipeline, using the official Snowplow Client and Tags.
Processing Required (Reverse ETL)
This option should be used to forwarding segments or other aggregated data to downstream destinations. Snowplow partners with two vendors to offer this capability, Census and Hightouch, however there are a variety of other vendors which offer alternative solutions in the Modern Data Stack.