Using SQL runner
Overview
If you are a Snowplow BDP customer, SQL Runner is already setup for you as part of your pipeline. Therefore, you can get started with configuring and deploying data models as outlined in the steps below.
As an initial overview, in your snowplow-pipeline repository, your data models reside in the sql-runner directory. If you already have the data modeling UI enabled, your GitHub repository will look like this:
.
├── datamodeling
| ├── datamodel_name
| └── sql-runner
| ├── playbooks
| └── sql
If you do not have the data modeling UI enabled, your GitHub repository will look like this:
.
├── jobs
| ├── datamodel_name
| └── sql-runner
| ├── configs
| ├── playbooks
| └── sql
└── schedules
Inside the datamodeling or jobs directory you can create the data models as subdirectories, giving them an appropriate name. The allowable characters for naming are a-z,0-9,-.
Each sql-runner subdirectory contains:
sql: the SQL scripts for your modelplaybooks: the playbook(s) your data model consists of
If you do not yet have the data modeling UI enabled, the subdirectory will also contain your data model configuration(s):
configs: the configuration file(s) for your data model
Furthermore, if you do not yet have the new data modeling UI enabled, the data model will have a corresponding JSON schedule file inside the schedules directory, that mainly defines the cron schedule to run it and the configuration file.
Behind the scenes, what happens is:
- When the schedule kicks off, the data model configuration is loaded and validated. Then, the corresponding data modeling DAG is autogenerated accordingly.
- Each task in the datamodeling DAG corresponds to the execution of a playbook by SQL runner. Tasks can be sequential or parallel, exactly as you have defined them in your configuration (either in the UI or in the config file).
- The autogenerated DAG is essentially a Factotum factfile, which is then run.
Read below for more details on the steps to configure and run your data models with Snowplow BDP.
1. Writing playbooks for your SQL scripts
As an example, one of the playbooks for the Snowplow web data model against Redshift:
:targets:
- :name:
:type: redshift
:host:
:database:
:port:
:username:
:password:
:ssl:
:variables:
:model_version: redshift/web/1.1.0
:scratch_schema: scratch
:output_schema: derived
:entropy: ""
:upsert_lookback:
:stage_next: true
:skip_derived:
:steps:
- :name: 00-setup-sessions
:queries:
- :name: 00-setup-sessions
:file: standard/03-sessions/01-main/00-setup-sessions.sql
:template: true
- :name: 01-sessions-aggs
:queries:
- :name: 01-sessions-aggs
:file: standard/03-sessions/01-main/01-sessions-aggs.sql
:template: true
- :name: 02-sessions-lasts
:queries:
- :name: 02-sessions-lasts
:file: standard/03-sessions/01-main/02-sessions-lasts.sql
:template: true
- :name: 03-sessions
:queries:
- :name: 03-sessions
:file: standard/03-sessions/01-main/03-sessions.sql
:template: true
- :name: 04-sessions-metadata
:queries:
- :name: 04-sessions-metadata
:file: standard/03-sessions/01-main/04-sessions-metadata.sql
:template: true
- :name: 05-sessions-prep-manifest
:queries:
- :name: 05-sessions-prep-manifest
:file: standard/03-sessions/01-main/05-sessions-prep-manifest.sql
:template: true
- :name: 06-commit-sessions
:queries:
- :name: 06-commit-sessions
:file: standard/03-sessions/01-main/06-commit-sessions.sql
:template: true
This way, a playbook organizes on a lower level the SQL scripts to run in linear fashion or in parallel, defines the variables and provides the credentials to run the queries against your storage target.
2. The data modeling configuration
2.1 Configuring data models via the data modeling UI (new)
Data models can now be configured via the Snowplow BDP Console:

In the first step, you can provide the data model name, a description as well as the owner(s) of the data model that will be alerted in case of failure.
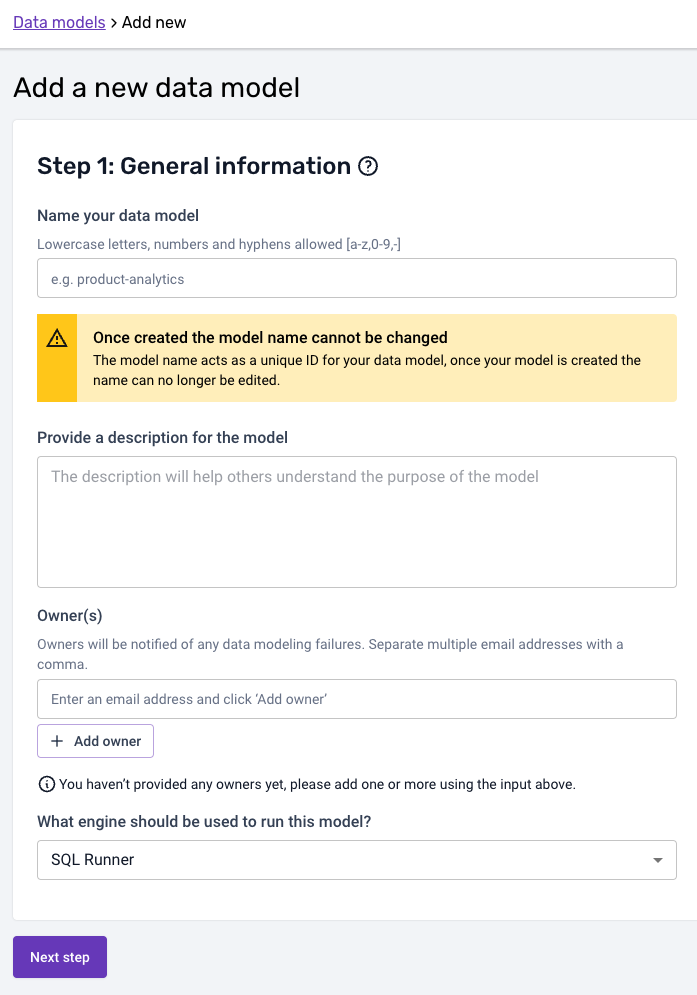
Please note that the model name needs to correspond to the corresponding datamodeling subfolder name in GitHub. The SQL and playbooks for the model in the above example would therefore live under:
your snowplow-pipeline repo > datamodeling > data model name > sql-runner ...
In the second step, you can then add the schedule and configure the lock type:
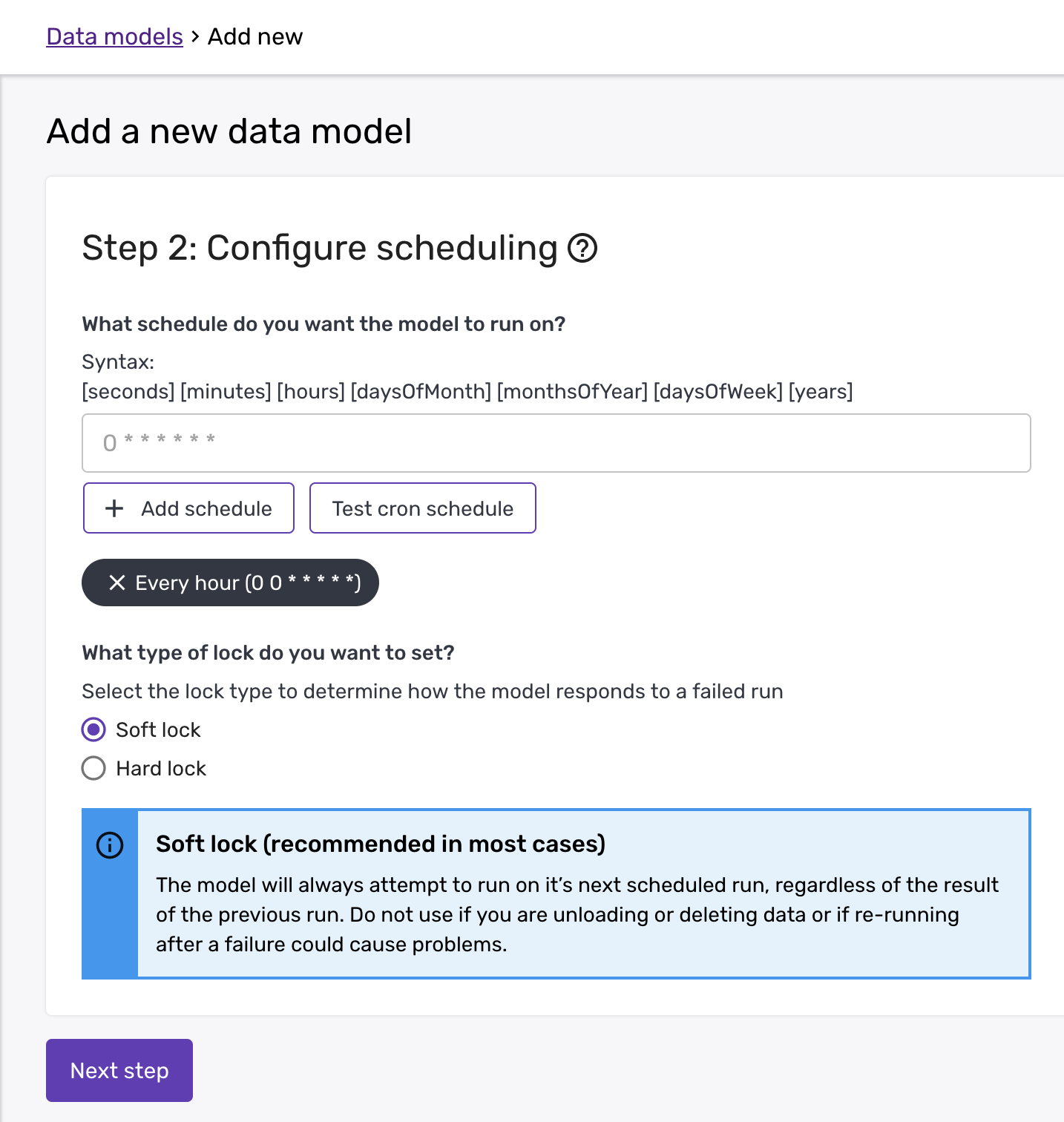
Please note that the cron schedule is in UTC.
The lock determines what happens when a data model fails. There can be cases when it is not safe for the model to re-run. That is what a "hard" lock does: The data model cannot re-run after a failure, unless it is explicitly unlocked. For it to be unlocked, you will need to make the necessary changes and then contact the Snowplow Support team to unlock it.
On the other hand, when a data model is safe to re-run, then you can specify the "lockType" as "soft". The benefit of the soft lock is that you do not need to email Support to unlock a model after a failure and thus, you will be able to resume a model once it has been fixed.
Warning
Do not change the lock type to "soft" for any data models that either unload or delete atomic data as this may cause data loss!
In the third and last step you can configure which playbooks you want to run as part of this model, in what order:
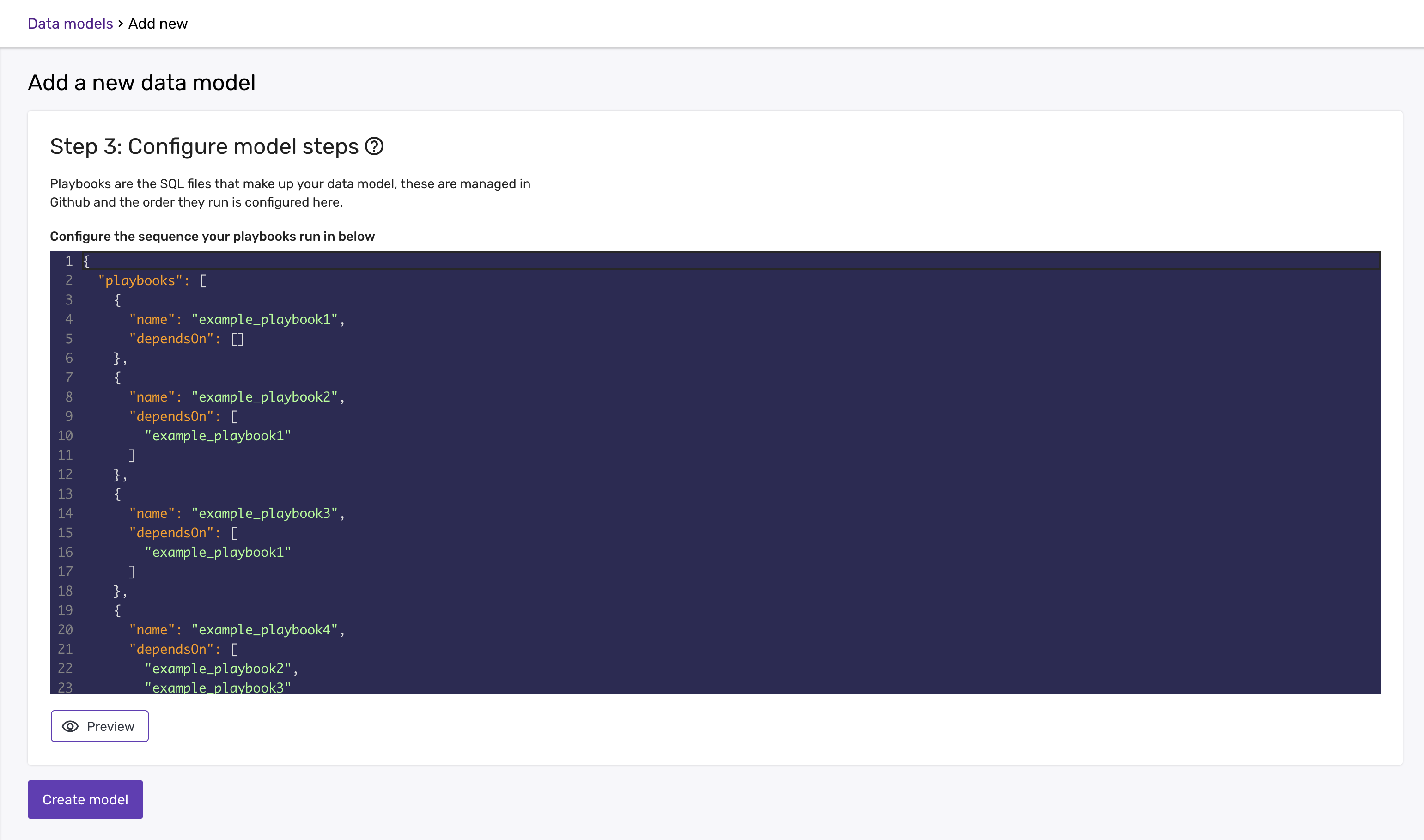
You can verify the DAG that will be generated based on the JSON by clicking 'Preview':

Once you are happy with the playbook configuration, you can create the model. The model will be disabled until you enable it:
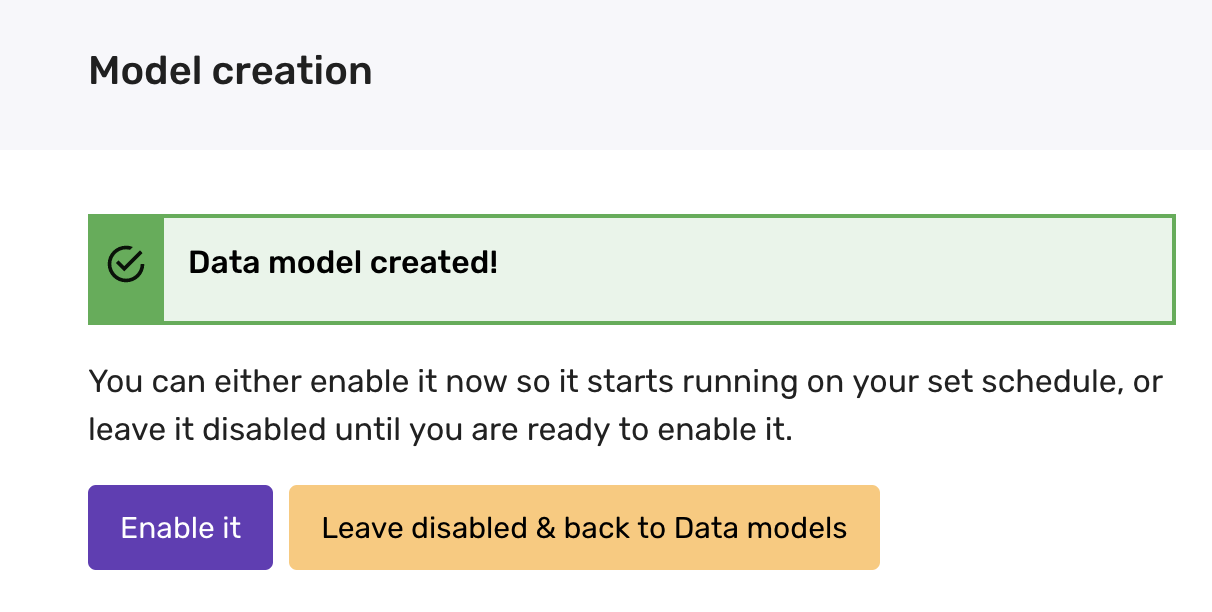
Please make sure all your SQL and playbooks are merged to the default branch in GitHub before enabling the model. Note that this tooling no longer runs a "sync and deploy" process. Any changes merged to the default branch are available immediately.
2.2 Configuring data models via GitHub (old)
The data modeling configuration is a JSON file that allows you to specify which playbooks will run as part of a single data model (or job) as well as additional options such as the lock type and the owner.
An example configuration file with all options provided:
{
"schema": "iglu:com.snowplowanalytics.datamodeling/config/jsonschema/1-0-0",
"data": {
"dagName": "datamodeling",
"enabled": true,
"storage": "Default",
"sqlRunner": "0.9.1",
"lockType": "soft",
"playbooks": [
{
"playbook": "page-views",
"dependsOn": []
},
{
"playbook": "sessions",
"dependsOn": [ "page-views" ]
}
],
"owners": [
{
"name": "Bob Foo",
"email": "bob@foo.com"
},
{
"name": "Alice Bar",
"email": "alice@bar.com"
}
]
}
}
Required fields
"enabled": Specifies whether the data modeling job will run (true) or not (false). This is a way to disable or re-enable your data modeling job, even without changing the schedule."storage": Specifies your data warehouse. Possible values are:"Default": When your storage target is Redshift or Snowflake."BigQuery": When your storage target is BigQuery.
"playbooks": This is the array that specifies the playbooks to run and their inter-dependencies. Every playbook, as a JSON object, needs to specify the fields:"name": the playbook name and"dependsOn": an array denoting any other playbook names, that this playbook depends on (can be empty).
"lockType": This specifies what happens when your data model fails. Possible values:"hard""soft"
When a SQL Runner DAG fails there are cases when it is not safe for the model to re-run. That is what a "hard" lock does: The data model cannot re-run after a failure, unless it is explicitly unlocked. For it to be unlocked, you will need to make the necessary changes and then contact the Snowplow Support team to unlock it.
On the other hand, when a data model is safe to re-run, then you can specify the "lockType" as "soft". The benefit of the soft lock is that you do not need to email Support to unlock a model after a failure and thus, you will be able to resume a model once it has been fixed.
Warning
Do not change the lock type to "soft" for any data models that either unload or delete atomic data as this may cause data loss!
"owners": [This field is required, if the"lockType"is"soft".]
The "owners" field allows Snowplow BDP customers to specify one or more owners ("name" and "email") when deploying a data model. The model owners will get email notifications as soon as there is a data modeling failure. Along with the "lockType", these options give you more control over your data models, since they enable you to know immediately when a data model fails, deploy fixes faster and resolve any issues directly.
Additional optional fields
"dagName": [Default value:"datamodeling"]. The name of the data modeling DAG."sqlRunner": [Default value:"0.9.1"]. The SQL Runner version that runs your playbooks.
Make a schedule
The schedule is a JSON file in the schedules directory through which you can specify the cron schedule that you want SQL Runner to run your data model. It also specifies the corresponding configuration file. As an example:
{
"schema": "iglu:com.snowplowanalytics.managed-service/job_schedule/jsonschema/1-0-0",
"data": {
"interval": "15 * * * *",
"job": "com.acme-datamodel_name",
"dag": "common/dags/sql-runner/autogen/gen-datamodeling-0.2.0.factfile"
}
}
The above schedule specifies that your data model will run every hour past 15 minutes. It does not specify a configuration file, which is meant to denote that the configuration file has the default name: datamodeling.json
If the filename of the configuration of your data model is other than datamodeling.json, then it just needs to be specified:
{
"schema": "iglu:com.snowplowanalytics.managed-service/job_schedule/jsonschema/1-0-0",
"data": {
"interval": "15 * * * *",
"job": "com.acme-datamodel_name",
"dag": "common/dags/sql-runner/autogen/gen-datamodeling-0.2.0.factfile",
"env": [
{
"key": "configuration",
"value": "config-filename.json"
}
]
}
}
3. Monitor your model in the Snowplow BDP Console
Everything is set and you can now monitor your data models running against your data warehouse from the Snowplow BDP Console, in the Jobs UI! There you can see the data modeling DAG generated, and monitor the status, duration and run times both at the data model and at the playbook level.